







为何DeepSeek引发美国恐慌?
- 汽车
- 2025-01-28 18:26:06
- 11
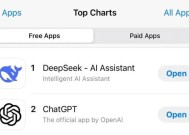
这几天,中国人工智能初创公司 DeepSeek 火了,不仅在美区下载榜上超越了 ChatGPT,还引发多个美国科技股的股价暴跌。美国总统特朗普称 DeepSeek 的出现 " 给美国相关产业敲响了警钟 "。为何 DeepSeek 的出现会让美国如此关注,甚至有些紧张?谭主联合中国工业互联网研究院独家揭秘背后的原因:
原因一:
高性价比冲击美国大模型垄断地位
DeepSeek 可谓是用最少的钱,干最多的事。其推出的模型,在性能上和世界目前顶尖的 GPT-4o 等大模型不相上下。但在成本上,OpenAI 训练 ChatGPT-4 花费的成本高达 7800 万美元,还可能达到 1 亿美元。而 DeepSeek 大模型训练成本不到 600 万美元,仅为同性能模型的 5% 到 10%。新模型训练方法大幅度降低了大模型行业的入局门槛,大规模预训练不再是科技巨头的专利。在模型推理层面,DeepSeek 新推出的 DeepSeek-R1,价格为 2.2 美元 / 百万词元,而同性能 OpenAI-o1 的价格为 60 美元 / 百万词元,DeepSeek 大概是 OpenAI 的三十分之一。这种 " 低成本 " 标志着推理大模型调用进入平价时代,显著改善了大模型的应用成本,对大模型在科研、企业等智力密集型产业中的应用具有重大的价值。因此,无论是从基础研究角度还是从商业层面上看,在训练和推理方面,对此前美国一些大模型公司的既有模式冲击比较大。

原因二:
模式创新,带来美国高新技术人员恐慌
DeepSeek 开发成本与美国大模型相比大幅降低,在于应用了不同的模型训练模式,打破了美国堆砌算力的 " 豪气 " 方式。在喂养学习数据这一大模型重要环节上,OpenAI 选择了 " 人海战术 ",堆砌算卡、将资源集中在算力,用海量数据投喂实现能力的提升。而 DeepSeek 相比于 " 砸资源 " 选择了另外一种方式。利用算法把数据进行总结和分类,经过选择性处理之后再输送给大模型,最大优化算力实现了成本的降低和模型性能提升。目前看 Meta 耗费了大量资金训练 Llama,但是效果上却没有成本极低的 DeepSeek 效果好,Meta 高层已经在思考其员工是否在浪费公司资金,而这也引发了不少企业技术人员的恐慌,他们担心自己被质疑技术能力和创新性从而失去工作。根据海外互联网平台对 DeepSeek 的讨论分析,社交媒体帖子的数量远高于新闻报道,数量约是新闻报道的十倍。时间上来看,社交媒体帖子的讨论早于新闻报道,发酵起点比新闻媒体早了五天,这是由从事科技工作的自媒体人以及员工圈层传播 " 破圈 " 造成。

原因三:
国产大模型正在厚积薄发
根据中国工业互联网研究院推出的《人工智能大模型年度发展趋势报告》,与国际顶尖大模型能力相比,2024 年国内大模型的能力进步非常显著。从 2023 年第四季度到 2025 年第一季度的测评显示,国内外大模型能力差距缩小了将近 75%。可以看出,DeepSeek 的出现并不是所谓的 " 异军突起 ",而是中国国内大模型整体发展的阶段性成果体现。此外,在报告统计的世界 AI 领域的投资上,中国 55 亿美元的投资额排在第二位,仅是第一位美国 641 亿投资额的不到十一分之一,中国未来在 AI 领域的发展上还有很大的空间。

如今,在 DeepSeek 对全球 AI 圈带来的震动下,很多业内人士都喊出了 "DeepSeek 接班 OpenAI" 的口号。事实上,DeepSeek 的出现,并不是要取代别人,而是提出了更多样化的方案,打破了国际主流大模型的市场垄断,在大模型的发展道路上提出了不同于美西方的中国解法,让世界看到了在大模型领域不是只有拼算力这一条路,再一次向世界证明,什么是中国智慧。
来源:玉渊谭天
相关文章
热门文章

前11个月民营企业享受新增减税降费政策金额占比超70%
2024-12-28
瑞幸香港连开5店,能否复制内地的成功?
2024-12-28
颁布不参赛就罚款新规之后,WTT失去了樊振东和陈梦
2024-12-28
应对节前办证高峰,元旦前上海加开两场出入境办证夜间专场
2024-12-28
乌总统就坠机事件向阿塞拜疆表示慰问:首要任务是进行彻底调查
2024-12-28
人民日报数字传播有限公司原董事长、总经理徐涛接受审查调查
2024-12-28
人民日报社山西分社社长何勇接受审查调查
2024-12-28
普京向阿塞拜疆总统致歉 二人通话讨论客机坠毁细节
2024-12-28
有话要说...